


The History of Fraud Behind the Subway's Most-Cited Performance Metric
There used to be a hell of a lot of fraud reporting On-Time Performance. When did it stop?
First of all, a belated but hearty thank you to the hundreds who emailed after the last Signal Problems. I am consistently blown away by your incredible support for this newsletter and my work in general.
I’ll get to the story behind this email’s subject line in a bit. But first, here’s the big stuff I’ve been working on lately:
Uber and Lyft take a bigger cut of each ride than they say. Both rideshare companies insist they are merely a technology platform, not a transportation company. They argue this to avoid a whole host of regulations, including classifying their drivers as employees (something I have written about a lot as well). A key tell that this argument is invalid is that drivers cannot determine their own prices for their services, nor is there a pre-negotiated rate Uber and Lyft charge drivers for access to their platform. It’s whatever the hell Uber and Lyft feel like. And that “take rate,” as it is known, varies tremendously by ride. Of course, Uber and Lyft do not publicly disclose their true “take rate.” So my colleague Dhruv Mehrotra and I crowdsourced a database of almost 15,000 fares and found both companies take much more than they say.
'There's No Such Thing As Cold, Hard Reality': Meet The Hyperloop's Truest Believers: Maybe you’ve never heard of a Hyperloop, or maybe you believe it’s our next, great hope for intercity transportation (my guess if you read this newsletter is you do not). Either way, I found nearly all coverage of the Hyperloop ridiculously simplistic to the point of being glorified marketing copy (“Denver to Cheyenne in 20 minutes? With the Hyperloop, You Betcha!”) so I went to a Hyperloop enthusiast conference to find out what its deal really is. I found it both more ridiculous and also more revealing than I expected.
Now, about the subway. The Times ran an article Friday about how the subway continues to get better but is still not, you know, great. One chart from the Times article caught my eye:

Looking at this chart, one could—indeed, should—conclude the subway performed supremely well through the 1990s and into the late 2000s before performance fell off and only now is the subway performing about as well as it did in 2011.
But that’s not the true story. Because On-Time Performance, the stat most often cited when evaluating subway performance, has a dirty secret. For much of its history, it’s been fraudulent.
On October 26, 1994, MTA Inspector General Henry Flinter published a report titled “Does The Transit Authority Accurately Report Subway On-Time Performance?” The answer to that question was a resounding “No.”
(To the best of my knowledge, the report has not been on a publicly available link—until now. You can read the report here.)
For the uninitiated, OTP is an important stat for much of the same reason the subway is important; not because it is great, but because it exists. It is the only metric consistently measured for any prolonged period, meaning it is the only window into how subway performance has changed over time.
For much of OTP’s existence, it was compiled using a very manual process. Dispatchers at terminals recorded the times trains arrived, compared it to the schedule, then phoned the Command Center at the end of their shift to report the number of late trains (a number defined the same as it is today: any train that was more than five minutes late to the terminal or didn’t make every stop along its run).
To answer the question from the report’s title, Flinter’s team conducted two tests. First, they spot-checked the arrival times of 315 randomly selected trains at terminals across the system and compared that to the times dispatchers logged. Second, they looked to see how many trains were made “on time” by dispatchers changing the schedules illegitimately before reporting the number of late trains to the Command Center.
Flinter’s team found “discrepancies” in all respects:
First, dispatchers in the field added running time to schedules so that late trains appeared to be on-time. These adjustments to schedules, in violation of the TA’s [Transit Authority, as NYCT was known then] own rules, made one third of the late trains appear on-time. Second, dispatchers recorded incorrect times for another third of the late trains so they appeared to have arrived earlier than they did. Third, 15 percent of the late trains were not reported at all to the Command Center, even though they were shown as late on the dispatcher’s records. Of all the trains that arrived at their terminals more than 5 minutes behind schedule, the TA correctly reported only 20 percent as late.
In other words, dispatchers falsified records at every step. They:
padded the schedules
forged records with falsified arrival times
simply didn’t report some late trains they did correctly log
This had a massive impact on OTP. For the months examined by Flinter’s team, the TA reported an OTP of 90.8 percent. That’s good!
But the MTA IG calculated the actual OTP was more like 73.2 percent, or “almost 18 percentage points lower than that reported by the TA.” That’s bad.
Surely, this was all just a big mistake? Inefficient, manual record-keeping resulting in errors both ways, right? False positives and false negatives balancing out over time?
Yeah….not quite. From the IG report [emphasis mine]:
However, we found that errors occurred in a definite pattern they invariably served to make timeliness appear better than it was. Not one on-time train was made late by a recording error.”
When 100 percent of the errors are in one direction, that doesn’t make them sound like errors at all.
How could this have happened? Basically, the students were grading the test:
The fundamental weakness in this system is that dispatchers, the very employees who are held responsible for regulating train operations and supervising operating personnel, are responsible for reporting OTP data. In addition, TA management places pressure on its line managers, who have authority over dispatchers, to achieve OTP performance goals without enforcing appropriate internal controls to ensure data quality.
In sum, the overwhelming evidence suggests OTP was being logged fraudulently, not by a few bad actors, but as a matter of course.
Still, surely this was the first the TA was hearing about this? And would take drastic, immediate measures to clean this mess up?
Well, see, the thing is, not so much. This 1994 report was, in fact, a follow-up to a 1986 MTA IG report which found pretty much the exact same thing—reported OTP of 80 percent, actual OTP of 62 percent—and the TA did more or less nothing about it [again, emphasis mine]:
In our 1986 report, the OIG recommended that the TA audit dispatchers’ records periodically to check their accuracy and see if they matched official reports. The TA formally accepted this recommendation but never implemented it. To make matters worse, in 1992 the TA reported to us and to the MTA Board that it had implemented the recommendation. In the course of this investigation, we discovered this was not true.
Not only that, but it is fairly common knowledge in MTA circles that TA records from the 1970s were more or less meaningless because of fraudulent record-keeping, so much so that the TA changed the definition of “OTP” so people would stop using the old numbers.
Indeed, there is some evidence to suggest the malfeasance continued after 1994. Let’s go back to that Times chart:
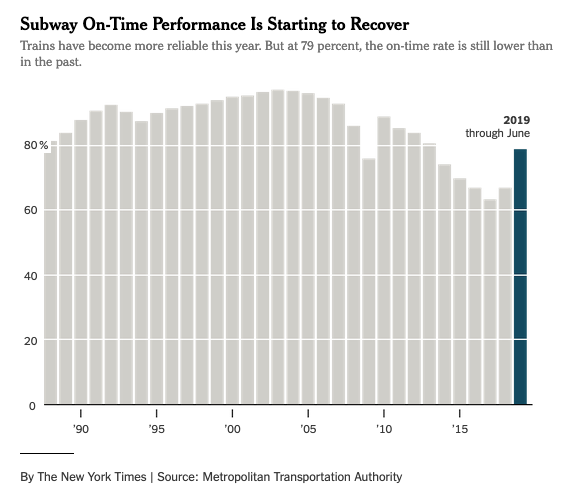
If we are to believe the TA instituted actual reforms that led to honest reporting of OTP after 1994, we ought to expect OTP to fall off a cliff, or at the very least decline. But that didn’t happen.
Instead, OTP got better as the 1990s went on. This leaves us with two options. One is subway service miraculously and drastically improved right as better reporting controls were put into place so much so that it negated the 18 percent the TA was inflating OTP. The other is no such controls ever existed and dispatchers kept lying and NYCT brass kept covering it up. One involves believing a confluence of circumstances that requires lots of independent factors to have suddenly changed all at once. The other involves everything to have stayed exactly the same. I, for one, know which scenario I find more plausible.
This leads to the obvious question: is this still going on?
Let’s cut to what Andy Byford told the Times:
Mr. Byford said that it was unfair to compare the current on-time rate with the early 2000s for several reasons: ridership is higher now, making it harder to run trains on time; a new electronic system to tally delays captures more incidents; and new rules protecting track workers have slowed down trains.
I don’t know if Byford is aware of the extent of previous fraudulent record-keeping, but his answer is not entirely wrong.
Starting about six years ago, NYCT moved over to a new electronic reporting system called ITRAC. It is electronic in the sense that it is using computers, but it is not electronic in the sense that terminal arrival times are automatically logged. Dispatchers still manually collect and input the data. But NYCT does have the ability to audit that arrival time data more easily, and because the process is less labor intensive, dispatchers have less incentive to make shit up towards the end of their shift.
(Now, I’m going to get super-nerdy for a bit. If you don’t care about the specifics of NYCT data collection and train management ops, feel free to skip this paragraph. There are, in many respects, two different subway systems within the subway: the A Division, comprised of the numbered lines, and the B Division with the lettered lines. The cars and tracks are different sizes, the mosaics in the stations have different designs, etc. This is because they were built by different, competing entities. They also have different back-end data systems. Starting around the early 2000s, the A Division got Automatic Train Supervision, which gave NYCT precise knowledge of where all the trains are for better dispatching and provided the data for the countdown clocks. But this system was never linked to the totally separate system used for delays reporting, so that process remained manual even though NYCT had a digital system for tracking every A Division train’s precise location. That only changed under Byford’s tenure—meaning terminal arrival data can now easily be spot-checked and cross-referenced—but dispatchers are still manually inputting that data, even on the A Division. The B Division has no Automatic Train Supervision [yet], but it does have those Bluetooth beacon-based countdown clocks that log when trains enter and leave stations. That data is less reliable than Automatic Train Supervision so its usefulness as a spot-checking tool isn’t as clear. I’m sure there’s much more about the ins and outs of this data-logging process I’m not explaining here; the MTA’s data management process could fill a [supremely boring] book.)
All that said, the warped incentive structure where the students grade the test is still in place.
At this point, you may be wondering what to make of all this, and how it fits into the narrative of subway performance over time. To be clear, I’m not trying to conduct some revisionist history campaign. Of course subway service got way worse over the last decade or so, of course the subway completely melted down around late 2016 and early 2017, and of course subway service has gotten better in the last year or so. But, the magnitude of these shifts are probably not as severe as OTP would suggest, nor was service ever as good as one might think looking at that chart.
In the Times article, City Council Speaker Corey Johnson, who moved to the city in 2001, called that era of subway service “a bygone, nostalgic era of reliable service.” I think there’s more truth to that statement than he perhaps realizes. It likely wasn’t as good as he remembers it. Nothing ever is. But it may just have been good enough, and sometimes it feels like that’s the absolute maximum we can ask from this city’s transportation system.
What bothers me the most reading the MTA IG report is not the crime, but the cover up, and the reminder that the subway crisis was a decades-developing debacle brought about by institutional rot. Decades of warning signs were swept under the rug or merely brushed aside for a future generation of managers, workers, and riders to deal with.
There is one sentence from the MTA IG report that sticks with me the most for its prescience. As the MTA IG predicted it 25 years ago:
The degree of misreporting that we found may well cause TA management to lose touch with the real level of service it is providing, creating an unwarranted sense of confidence.
If I was to sit down today and write one sentence to summarize the failures of MTA management over the past two decades, I would struggle to write a better one than that.
As ever, the issue at hand is what we learn from all this. Will we learn from the past and heed the warnings in black and white right in front of us about the issues facing us today, not because it is easy but because it is right? Or, will we continue the time-honored tradition of brushing those warnings aside, plow ahead, and add to the bill for future generations to pay?
Oh, you didn’t think I was letting you out of here without a dog in a bag, did you?
